



 Oligo Pools
Oligo Pools
 Variant Libraries
Variant Libraries








- OVERVIEW
- DATA
- POPGEN
- AGRIGENOMICS
- RESOURCES
Simplified Workflow for Ultra-High Throughput Sequencing
Twist’s FlexPrepTM UHT Library Preparation Kit offers an NGS alternative to traditional microarray-based technologies for population studies, agrigenomics and other ultra-high throughput applications. Combining Twist’s Normalization by LigationTM (NBL) technology with enzymatic fragmentation methods, the kit offers built-in sample normalization across a wide range of DNA inputs, reducing both cost and complexity of typical sample processing steps. Early sample barcoding enables downstream pooling of twelve separate samples into one reaction for a more streamlined and efficient workflow.
PRODUCT HIGHLIGHT
.png)
Normalization by Ligation (NBL)
- Eliminate upfront normalization
- No need for intermediate quantitation
- Work with sample batches using a wide range of inputs (30 ng to 300 ng)
.png)
Early Sample Pooling Saves Cost
- Pool 96 samples into 8 tubes after the ligation reaction
- Miniaturized reaction volumes upstream
- Reduction in consumables downstream
.png)
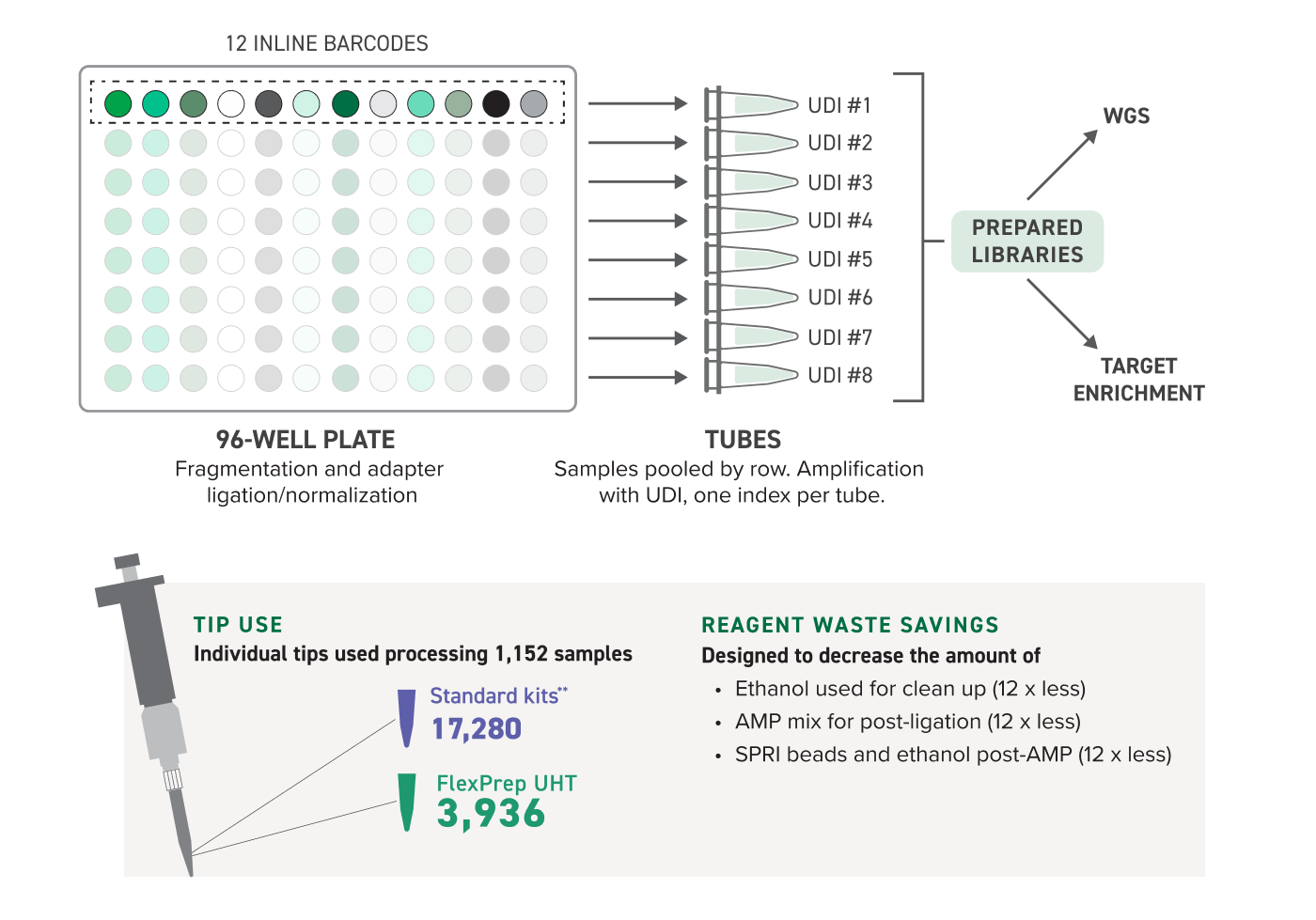
Designed for Ultra-High Capacity Multiplexing
- Remove multiplexing limitation per flow cell lane with ultra-high throughput indexing
- Increase capacity 12x with existing lab setup*
- Supports 96 samples per target enrichment reaction
For research use only. Not for use in any diagnostic or clinical procedures.
*Based on a 8 well vs 96 well workflow
FAQ
Normalization by LigationTM is Twist’s proprietary technology to eliminate upfront normalization and intermediate quantitation, which allows work with sample batches using a wide range of inputs (30 ng to 300 ng).
Gencove data and internal bovine ear clip data are available. At launch, we support Human and Bovine. Contact Customer Support to access this data.
The recommended input amount is 30 ng - 300 ng, which should produce ≥ 1000 ng of final library with fragment sizes between 400-450 bp. Fragmentation size is dependent upon fragmentation time. For details, please refer to the Twist FlexPrep UHT Library Prep Protocol.
The Twist FlexPrep UHT Library Preparation Kit is compatible with DNA of different quality, where the kit has been tested with FFPE of various quality and degraded DNA. Contact Customer Support if you have additional questions
Yes, the kit can handle units of 12 samples, up to 192 total samples. The kits are configured to handle up to 192 and 1152 samples in each batch. If you would like to process less than 192 and 1152 samples, respectively, we recommend filling the remainder of the plate with sample replicates, which would offer even greater confidence in sequencing results.
Integrated Normalization Eliminates Steps
The Twist FlexPrepTM UHT Library Preparation Kit takes a novel Normalization by LigationTM approach which eliminates the need for upfront and intermediate sample quantitation, streamlining your sequencing workflow.
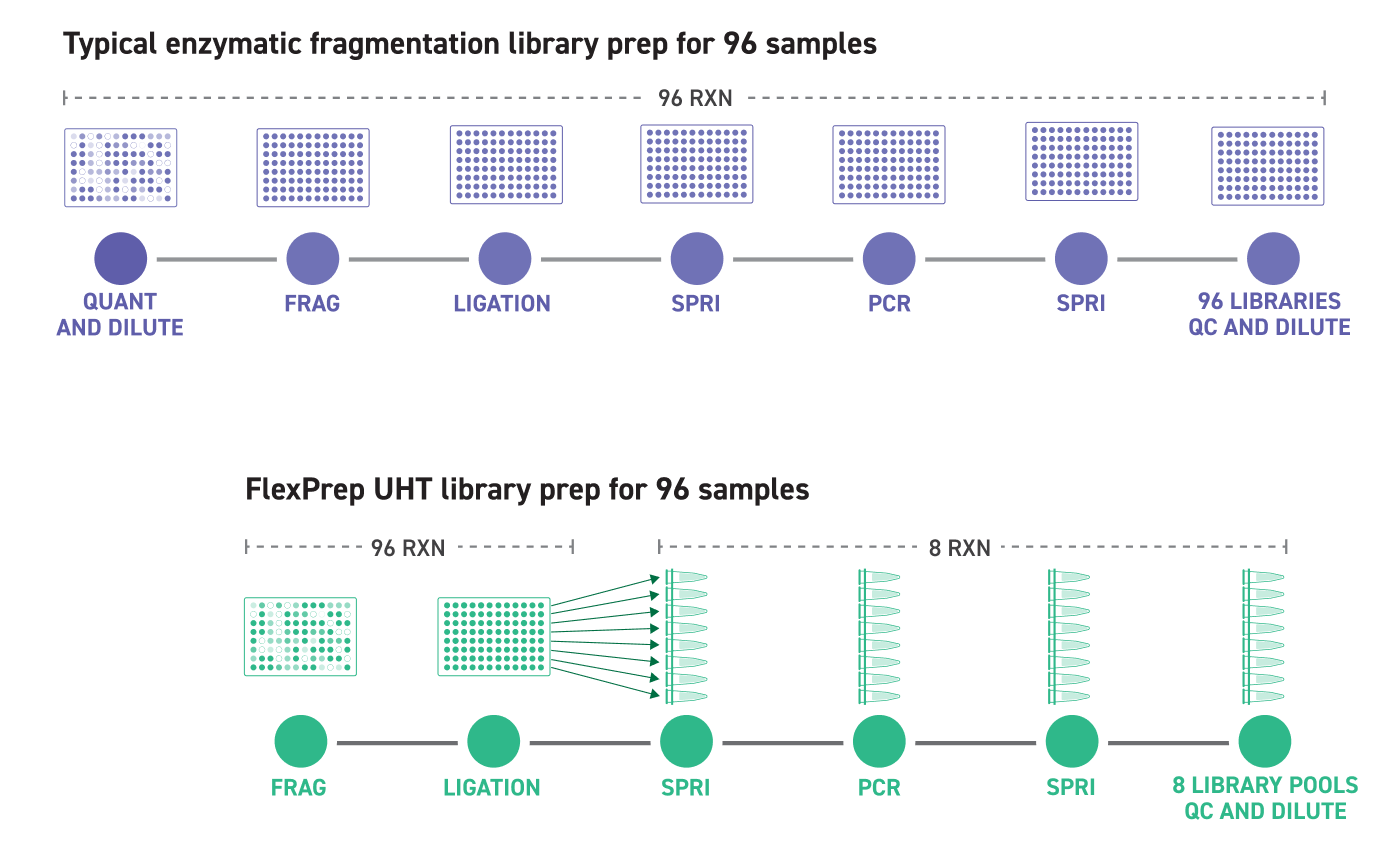
Simplicity of Workflow
Fragmentation and ligation reactions are prepared in one well per sample. The adapters used during ligation contain inline barcodes that allow for the pooling of all 12 wells in a row of a 96-well plate. Individual pools are prepared with indices (UDIs) added by PCR for pool-level demultiplexing. Sequencing throughput can be maximized by running up to 1,152 samples in a single sequencing run from one FlexPrep kit. This increased efficiency can translate to cost and consumables savings.
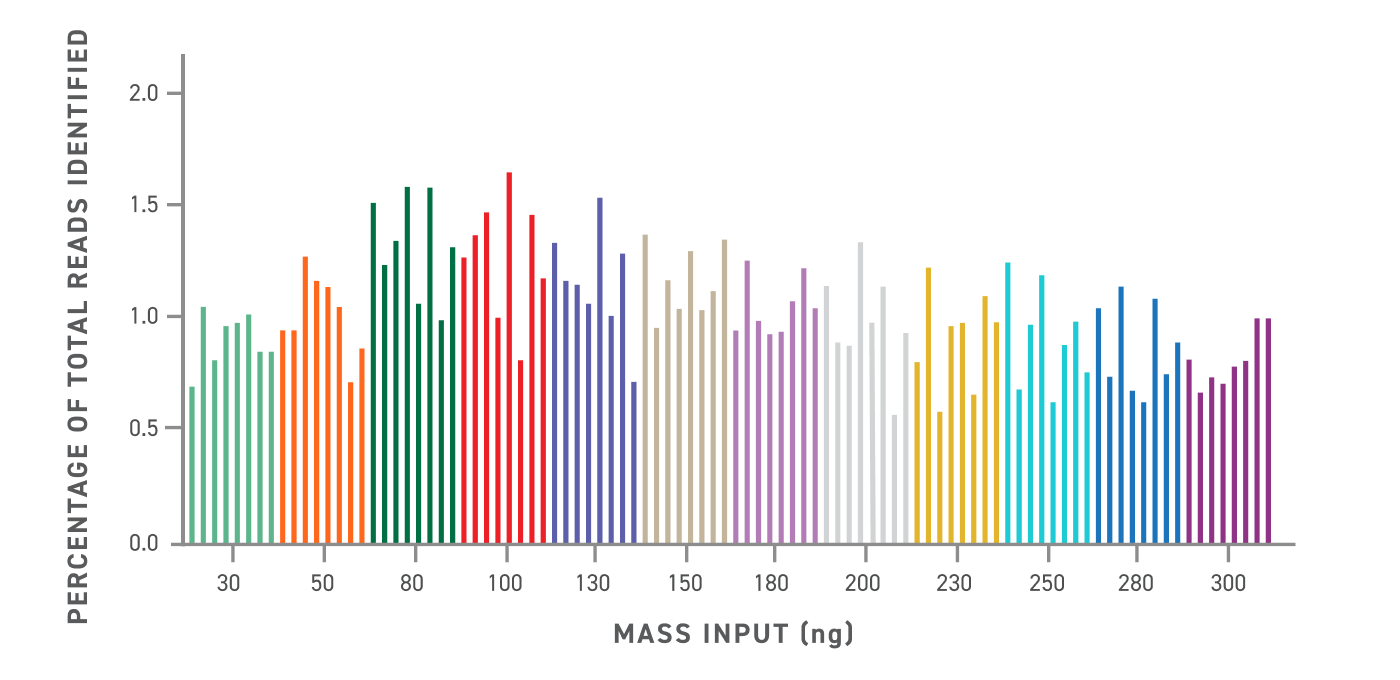
Normalized Yield with FlexPrep UHT*
NGS read depth normalization with variable DNA mass input. Percentage of total read counts identified to each library is calculated after unique dual index and inline barcode demultiplexing. Average with perfect normalization is estimated at 1.04% (100/96).
Tunable Coverage for Regions of Interest*
FlexPrep UHT generates high-complexity libraries that have uniform coverage after target enrichment. In combination with Twist Custom Panels, FlexPrep offers tunable coverage of SNPs, k-mers, structural variants, and other genomic areas of interest. Enriched material was downsampled to an average of 75x coverage. Key target enrichment metrics from Picard are reported.
|
Target Enrichment using a 96-plex 30 ng to 300 ng gDNA Mass Input into Library Preparation |
|
|---|---|
| Metrics at 75x Raw Target Coverage | Average +/- Standard Deviation |
| Selected Bases | 79.22% +/- 0.54% |
| Mean Target Coverage | 32.74 +/- 4.78 |
| Chimeras | 1.31% +/- 0.38% |
| Fold-80 Base Penalty | 1.416 +/- 0.044 |
| Covered Bases at 10X | 96.06% +/- 0.94% |
| Covered Bases at 20X | 85.41% +/- 6.36% |
| Covered Bases at 0X | 0.43% +/- 0.04% |
FlexPrep for Human Population Genomics
With its ability to handle large cohorts efficiently and cost-effectively, FlexPrep is designed to meet the unique needs of genome-wide association studies (GWAS), genetic diversity research, and other high-throughput genomic projects.
Although many PopGen programs have readily adopted NGS technologies, new tools like FlexPrep maximize the increased throughput capabilities of today’s sequencing platforms, lowering the cost per data point.
NGS Advantages vs. Traditional Platforms for Variant Screening Studies
NEXT-GENERATION SEQUENCING WITH FLEXPHEP |
STANDARD NGS |
|
|---|---|---|
| Throughput | Up to 1,152 samples in a single sequencting rub;supports 96-plex | Typically processes one library per well with limited multiplexing |
| Workflow Complexity | Normalization by Ligation enables DNA input of 30-300 ng - no normalization required | More up-front and intermediary steps, including quantification, normalization |
| Consumables Usage | Sample pooling reduces tip and reagent usage 12x | Increased usage of tips and reagents lead to increased waste and costs |
Sequencing
Element Biosciences
By leveraging the Trinity Freestyle™ Hybridization Kit, FlexPrep maximizes the throughput capabilities of Element sequencers. This workflow compounds the time savings of FlexPrep’s easy workflow with the hands-off time afforded by on-sequencer Trinity enrichment chemistry.
Target Enrichment
Twist Genotyping Panel - Human 600k
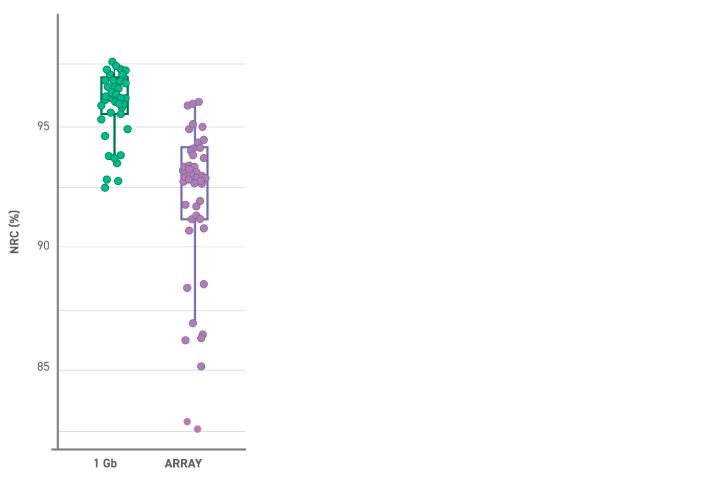
Twist Genotyping Panel - Human 600k achieves high concordance with array data. Genomewide non-reference concordance (NRC) obtained after imputing all data (sequencing or array) to the Gencove v6.1 imputation reference panel.
Analysis
Gencove
For streamlining human population genomics studies, Twist has partnered with Gencove. Combining the FlexPrep™ UHT Library Preparation Kit with Gencove's imputation pipeline enables high-confidence variant calling from reduced sequencing coverage, maximizing efficiency and throughput and allowing you to generate valuable insights from genotyping data with exceptional accuracy and reduced sequencing costs.

FlexPrep for Agrigenomics
In contrast to microarrays which have traditionally been used for agrigenomics studies, FlexPrep’s low cost, content flexibility, and high throughput capabilities allows for a single platform for genotyping, marker discovery, and fine mapping. When compared to standard library preparation, workflow improvements like self-normalization across sample types allows FlexPrep to tackle large agrigenomic projects like precision breeding, genomic selection, and parentage testing.
NGS Advantages vs. Traditional Platforms for Agrigenomics
NEXT-GENERATION SEQUENCING WITH FLEXPHEP |
MICROARRAYS |
|
|---|---|---|
| Data Completeness | Comprehensive,base-pair resolution across genome or selected regions | Limited to pre selected variants;not well-suited for novel variant detection. |
| Customization of Content | Easily customizable panels with fast TAT - target any genes,regions, or species | Content is fixed or semi-custom;change require redesign and new manufacturing |
| Cost and Throughput | Lower cost per sample at scale due to multiplexing (up to 1152 samle per ) | Cost scales poorly for large programs or across multiple species |
Twist Workflow for Agrigenomics

Extraction
Twist DNA Purification Kit
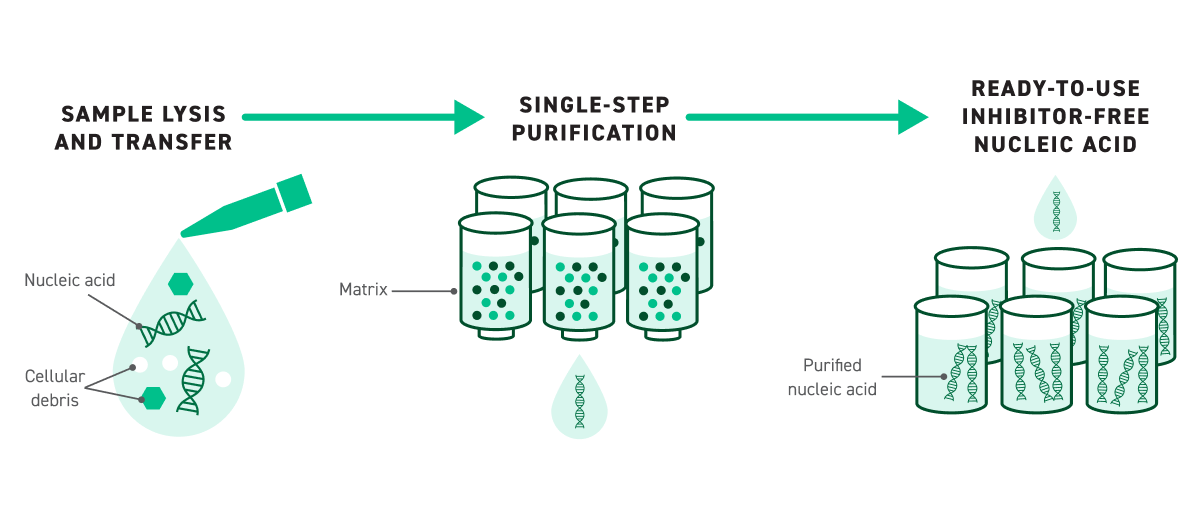
The Twist DNA Purification Kit module streamlines sample prep by taking even challenging, “dirty” samples directly into FlexPrep library preparation. Built on an innovative single-wash extraction chemistry, the kit eliminates the traditional bind–wash–elute cycle—reducing hands-on time, consumable use, and workflow complexity.
Sold as a bundled workflow with FlexPrep, the Twist FlexPrep UHT Pure Ag DNA LP Kit simplifies DNA extraction without compromising quality.
Sequencing
Element Biosciences
By leveraging the Trinity Freestyle™ Hybridization Kit, FlexPrep maximizes the throughput capabilities of Element sequencers. This workflow compounds the time savings of FlexPrep’s easy workflow with the hands-off time afforded by on-sequencer Trinity enrichment chemistry.
Analysis
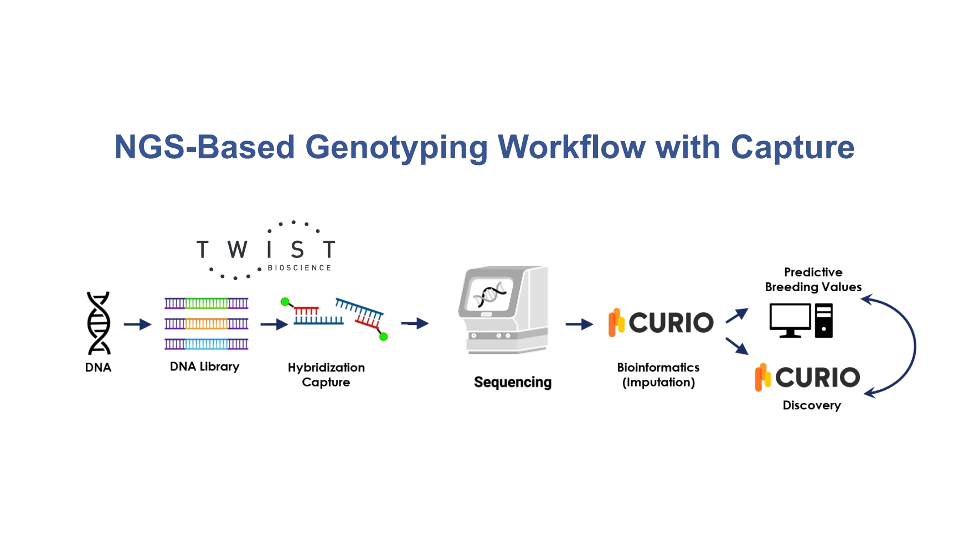
Curio Genomics
Scale your agrigenomics research with FlexPrep™ UHT Library Preparation Kit for low-pass sequencing and Curio Genomics for streamlined analysis. Twist's flexible library prep integrates seamlessly with Curio Genomics' platform, which offers high-throughput processing and efficient imputation, enabling cost-effective genotyping across large populations.
Gencove
Combining the FlexPrep™ UHT Library Preparation Kit with Gencove's imputation pipeline enables high-confidence variant calling from reduced sequencing coverage, maximizing efficiency and throughput and allowing you to generate valuable insights from genotyping data with exceptional accuracy and reduced sequencing costs.

A Cost-Effective Pan-Genome-Based Platform for Genotype Imputation, QTL Mapping, and Breeding Support
Pop Gen App Note
Complete and Cost-effective Agrigenomics Genotyping Across Large Breeding Populations
Genotyping Bovine Samples Prepared With Twist FlexPrep™ Library Preparation and Target Enrichment Workflows
Twist FlexPrep UHT Workflow Automated on Revvity Sciclone G3 NGSx Workstation
Ultra-High Capacity Multiplexing With the Twist FlexPrep UHT Workflow Automated on Hamilton NGS STAR
Twist FlexPrep UHT Library Preparation Kit: Sample Demultiplexing Guide
Twist FlexPrep UHT Library Preparation Kit Datasheet
Troubleshooting with Twist - FlexPrep UHT Library Prep Best Practices

Twist Bioscience HQ
681 Gateway Blvd
South San Francisco, CA 94080